

Understanding the Essentials of Proxy Servers
Welcome to the world where data is the new gold, and proxy servers are the mining tools. In the vastness of the internet, these servers are the unsung heroes that provide us with the anonymity and access we need to mine information securely and efficiently. Like the many doors leading to the internet’s endless rooms, each proxy type opens up different possibilities. Let’s step through these doors together.
The Steady Guard: Static Proxies
Static proxies are the loyal knights of the internet realm—unwavering, dedicated, and reliable.
79.81.65.201:1085
This is what the list of static proxies looks like
49.138.100.237:1085
48.140.207.181:1085
48.88.13.50:1085
80.47.55.139:1085
40.88.13.145:1085
19.233.89.115:1085
85.171.224.185:1085
191.151.189.211:1085
86.239.36.21:1085
They stand firm, offering the same IP address to ensure your digital presence is consistent. Ideal for businesses that need to maintain a steady online persona without raising the drawbridge of suspicion, static proxies are perfect for managing long-term campaigns and monitoring brand reputation. However, even knights have their limitations. Their static nature can make them more vulnerable to recognition and blocking in situations where discretion is paramount.
The Master of Disguise: Rotating Proxies
Imagine a chameleon in a vibrant forest. This is the essence of rotating proxies. With the ability to switch IP addresses seamlessly, they provide the camouflage necessary for extensive data mining operations such as web scraping. Businesses that need to harvest large datasets from across the web without leaving a trail find rotating proxies invaluable. They’re not just a tool; they’re a strategy. But the art of disguise requires finesse—each change of IP can disrupt sessions, which might not be ideal for all applications.
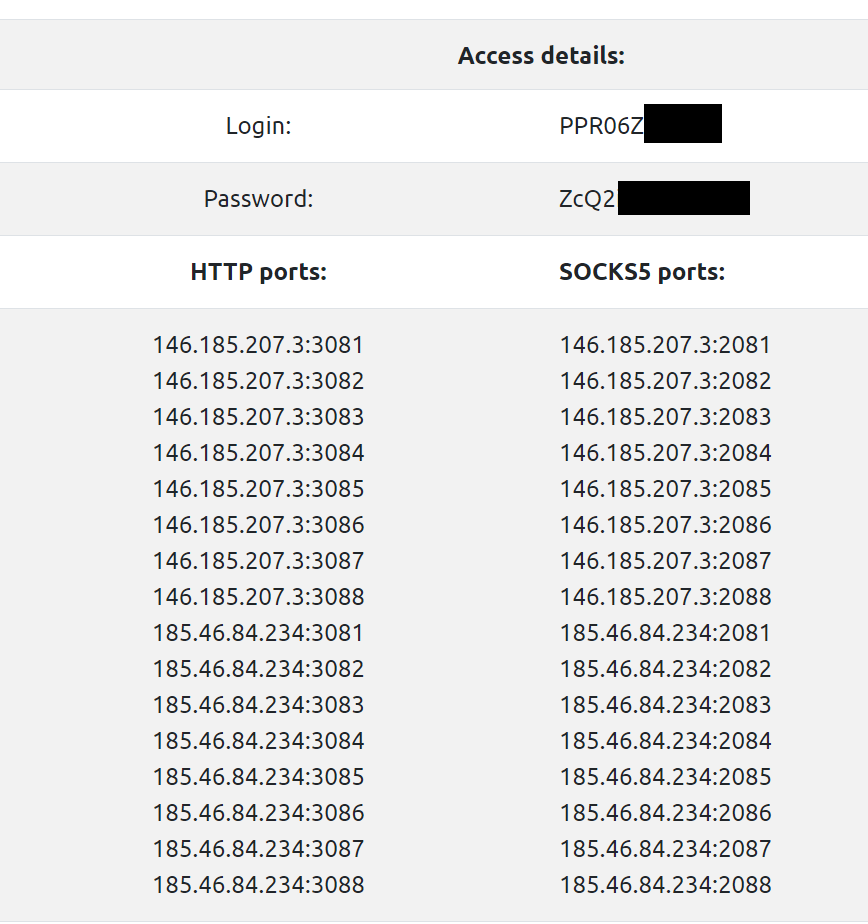
As we explore further into the world of proxy servers, we’ll unravel the threads of Socks5 and HTTP proxies, each with their unique patterns woven into the fabric of internet security and accessibility. Stick with us as we lay out the tapestry of proxy servers, thread by thread.
Socks5 Proxies: The Versatile Conduit
n the realm of proxy servers, Socks5 proxies are the all-terrain vehicles, navigating a wide variety of traffic with ease. These proxies are not just about anonymity; they’re about enabling any form of network communication, regardless of protocol or endpoint. Whether you’re streaming a foreign film or sending emails securely, Socks5 proxies handle it all with a level of flexibility that’s unparalleled. Their capability to authenticate connections also means that only authorized users can pass through, ensuring a secure, private channel.
HTTP Proxies: The Speedy Courier
HTTP proxies are like the express delivery service of the internet. They specialize in the delivery of web pages, fetching data with efficiency and precision. When speed is the priority and your tasks are centered around browsing and simple web tasks, HTTP proxies are your go-to. They not only enhance the speed of connection but also serve as a filter to screen out unwanted content, acting as both shield and courier in the bustling trade of internet data.
Data Center Hosted Proxies: The Fortified Stronghold
Data center proxies are the fortresses of the proxy world. Hosted in robust data centers, these proxies provide a powerful barrier between your operations and the outer world of the internet. They’re known for their high speed and reliability, making them a top choice for businesses that prioritize performance. While not tied to a physical ISP, they can sometimes be detected and blocked by services that are wary of non-residential traffic, which is something to consider based on your online activities.
Mobile and Residential Proxies: The Local Natives
Mobile and residential proxies are the locals of the internet neighborhood. They come from genuine residential ISPs and mobile networks, blending in seamlessly with regular users. For tasks that require the utmost in undetectability, like verifying ads or checking the localization of content, these proxies are worth their weight in gold. They provide the cover of being just another user in the crowd, all while backing you with the power of a proxy.
By now, you should have a clearer view of the landscape. From the steady static proxies to the adaptable rotating ones, and from the versatile Socks5 to the speedy HTTP, the choice of proxy comes down to your specific needs. Are you looking for a proxy that blends in like a residential or mobile proxy, or do you need the high performance of a data center proxy? Each type holds the key to different doors in the online world, and it’s all about choosing the right key for the right door.
The Essence of Mobile Proxies: The Agile Traveler
Mobile proxies are akin to the agile travelers of the virtual world, bringing with them IPs tied to mobile carriers. In an environment where trust is currency, these proxies are the gold standard for tasks like social media management and ad verification, where appearing as a typical user on a mobile network offers an edge. They weave through the internet with the inherent trust of a mobile user, opening doors that are often closed to others.
The Neighborhood Watch: Residential Proxies
Residential proxies are your neighborhood watch, offering IPs that trace back to an actual ISP in a specific locale. This local flavor is invaluable when you need to appear as a regular user from a specific region, enabling activities like content localization checks and market research with genuine accuracy. They ensure that your digital presence resonates with the authenticity of a resident, providing an inside view that’s often shielded from the outside.
Making the Right Proxy Choice: Your Digital Strategy
Choosing the right proxy is a strategic decision that aligns with your digital journey. Whether it’s the unassuming nature of residential and mobile proxies or the steadfastness of static proxies, each type serves a purpose in the intricate dance of online interactions. For those navigating vast data landscapes, rotating and Socks5 proxies offer a cloak of invisibility and adaptability, while HTTP proxies provide a swift passage through the world wide web.
The knowledge of when and how to use these proxies effectively can make the difference between an online presence that thrives under the radar and one that’s hindered by unnecessary barriers. With this arsenal of proxy types at your disposal, you’re now equipped to traverse the digital terrain with confidence, making informed choices that propel you toward your goals with precision and discretion.
In closing, the world of proxy servers is rich and diverse, much like the internet itself. By understanding the unique advantages of each proxy type, you can tailor your proxy strategy to meet the exact demands of your online endeavors. Embrace the power of proxies and chart a course through the digital domain that leads to success.